Note: This post is co-written with Piotr Sapieżyński
Is it possible for a small computer science course to exert measurable influence (trending topics) on Twitter, a massive social network with hundreds of millions of users? The surprising answer to that question is “yes”. That’s exactly what we did this year, using simple Python scripts and the Twitter API. Below we explain why & how + some of our findings along the way.
Why Twitter bots?
The standard (spam)bot on Twitter has almost no followers, almost zero activity, and exist for a single simple purpose, for example to increase follower counts for certain individuals.
For this year’s Social Graphs and Interactions course, we wanted to do something different – we wanted to see how “intelligent” we could make our bots, using simple machine learning and network analysis methods (the topics covered in the class).

A large part of our motivation for investigating Twitter bots in class is that the amount of manipulation that humans are experiencing on line is ever increasing. Think, for example, about how Facebook’s time-line filtering algorithm shapes the world view of hundreds of millions around the globe. And that’s just the most main stream example.
Instead of simply pointing out this fact, we thought that investigating how relatively simple bots can interact with and influence a real social system would be an interesting way for the students in our class to become aware of (and potentially counteract) some of those manipulations.
Some basic findings
Our first finding was that getting followers on Twitter is surprisingly easy! By employing a simple strategy, which takes advantage of a tendency for most users to “follow back” if followed by someone (who looks like a not-too-spammy Twitter profile). The recipe is simply
- Manually create a realistic profile, including a few tweets
- Pick users with between 50 and 300 followers (people with high numbers of followers are less likely to follow back).
- Follow about 100 new users per day.
- Unfollow whoever doesn’t follow you back within 24 hours (because users with a very asymmetrical ratio of following to followers look like spam-bots).
- Repeat steps 2-4.
Our initial target in the class was to get at least 50 followers that way, but in a relatively short time period the most successful bots had gained thousands of followers! Below is a plot of number of followers as a function of time for some of the most successful teams (for the first 50 days of the class).
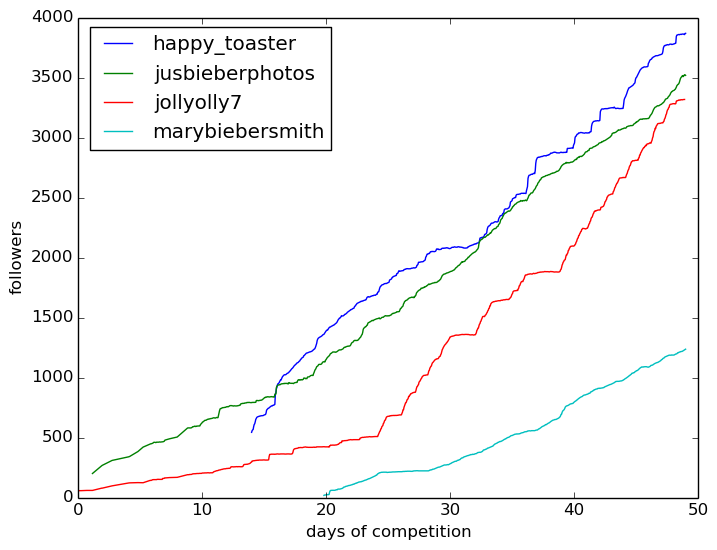
These large numbers of followers (along with systematic interactions added later) also translated to very high Klout-scores.
Aside: In the beginning of the course, we focused on Justin Bieber followers, here’s a snapshot from a report describing an early avatar
The next finding was that some teams in the class more or less inadvertently connected their bots to large “dark matter” components of the Twitter network, very large systems of spambots posting meaningless content and following back immediately in an automated fashion.
We did not explore these parts of the network in detail, but we note in passing that such areas are highly interesting for actual research, as they may create significant noise for analytics skewing results for algorithms working to predict the stock market or box office revenue based on the Twitter firehose.
The Twitter dark matter may create lots of noise on twitter, but are great for getting lots of followers quickly, and many followers is a key part of a convincing Twitter persona, as many Twitter users tend to think that someone with thousands of followers must have something interesting to say.
Social influence
As the course progressed, we focused on creating bots that could use machine learning to recognize “good” content for tweeting and retweeting. Bots that are able to detect topics within their tweet-stream … and distinguish between real, human accounts and robots among their followers.
However, the question remained: Can those thousands of followers be converted to influence on Twitter? For the class’ final project, we decided to put that to the test.
The overall goal was to for each team to build a convincing bot, get human followers, and at a specified time, for everyone work together to make specific hashtags trend on twitter. So how to achieve that goal? Here’s an overview of what each team has worked on
- Build convincing avatars and use the high follower-counts as part of the disguise.
- Use machine learning to tell who’s a bot and who’s not (in order to focus only on humans and ignoring bots).
- Use natural language processing & machine learning to discover quality content to re-tweet and tweet.
- Use network theory, to explore the network surrounding existing followers, making sure that bot actions reach entire communities.
Trending topics are defined for geographical areas. Since Copenhagen is not very active in the twitter-verse (sadly, Copenhagen does not have trending topics on Twitter), we chose Boston, MA (where both of us have lived) for the experiments. Thus all bots were located in Boston (both terms of in profile text and tweet-geotags) and tweet on an East Coast time table.
Specifically, the bots started following people located in Boston based on self-reported language, location, profile description and geo-tagged tweets. By the end of a three week period, more than 800 individuals in Boston followed at least one of our bots.

In addition to each bot’s idiosyncratic strategy for following new Twitter users, the bots maintained a shared list of Bostonians who had already followed (back) one of the bots. The idea being that if you follow more than one bot, content from the consortium of bots will increase proportionally in your Twitter stream.
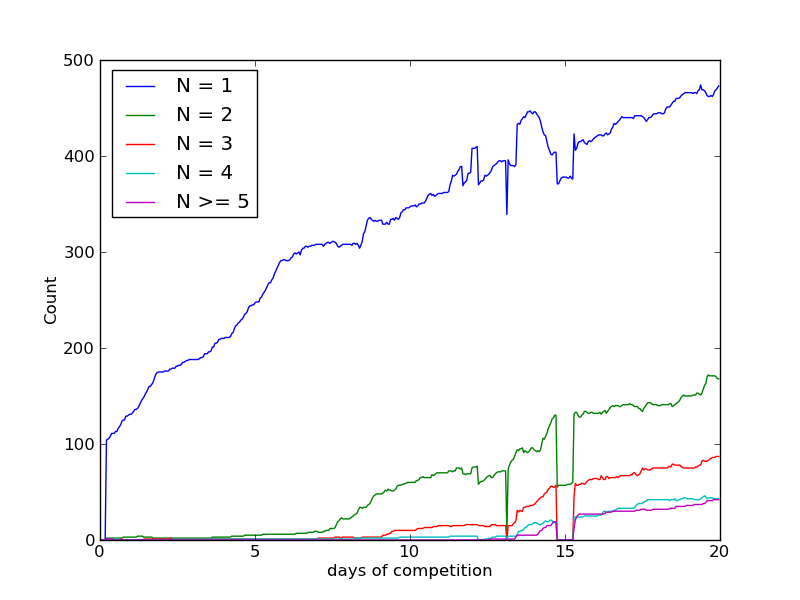
With all that in place, we tried three distinct interventions, ordered by what we perceived to be increasing potential for virality. Each intervention consisted of a couple of manual tweets per bot and coordinated/automated re-tweeting and favoriting. The first hashtag #bostonthanks was designed to be an unusual (so as to be specific to our intervention) thanksgiving greeting that we hoped would become one of the chosen thanksgiving greetings for Boston. It didn’t really take off. The idea behind the second hashtag #MeInThree was to start a hashtag that would allow people to describe themselves in three words/concepts (something that is fun and fits within Twitter’s 140 characters). That didn’t work either.
The third hashtag #banksyinboston was designed around secretive British artist and prankster, Banksy, who travels the globe pseudonymously and interacts with the world through movies, graffiti, and happenings. The idea was to create a couple of primitive “fake” Banksy artworks and start a #banksyinboston discussion “Is he really here?” in what we hoped would be the spirit of Banksy himself. Boston also has original Banksy art, which might add to the discussion.

Above is one of the crudely made Banksy fakes with background image of Trinity church from Google Street View: note the artifact in the upper left edge of the photo. (Interestingly another and much more elaborate Banksy-in-Paris hoax/non-hoax started the same day!)
Much to our surprise (after two failed attempts), the third attempt actually succeeded in our stated goal of influencing the trending topics on Twitter!!
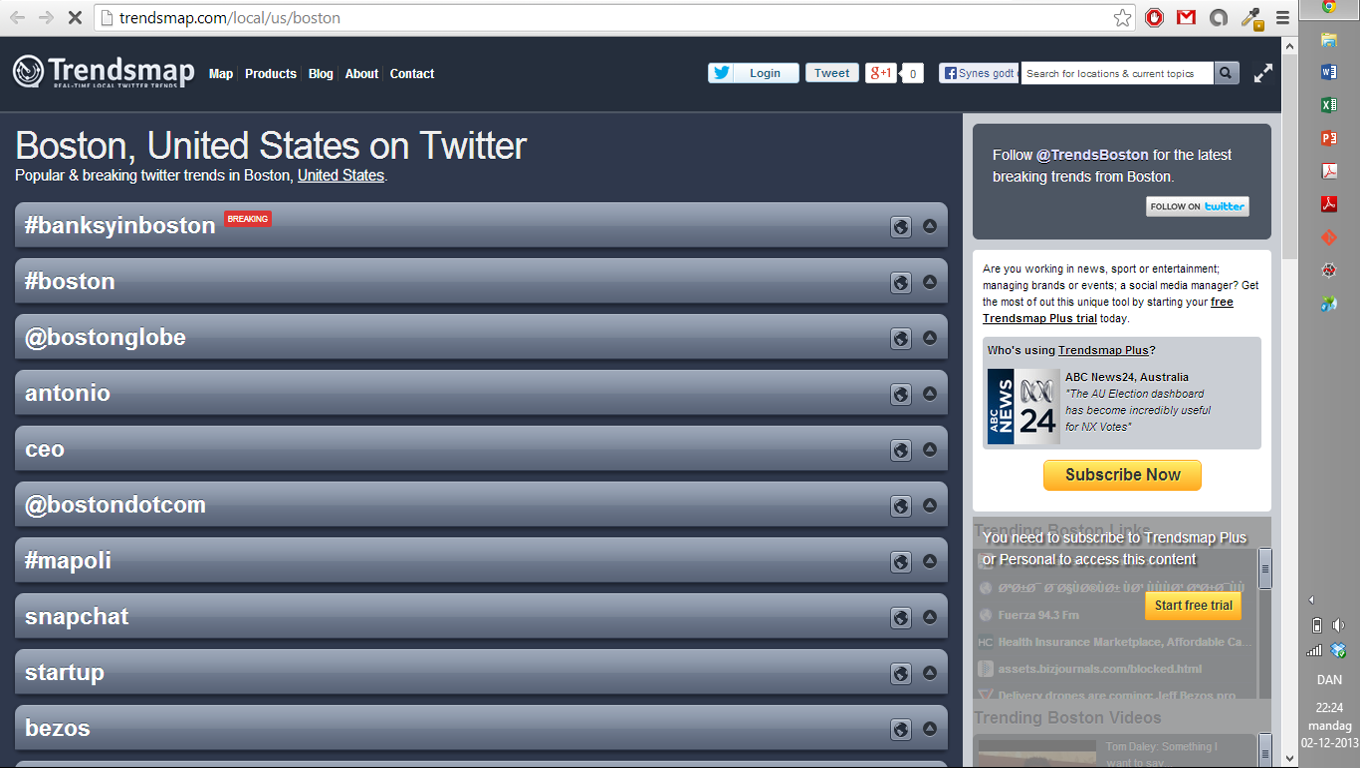
We did fall short of trending on Twitter’s own website, but #banksyinboston managed to get to the top of the trending list for the competing site trendsmap.com.
Analyzing the subsequent cascade of tweets reveals a couple of interesting things. Firstly, existing Boston graffiti was indeed re-discovered. Secondly, and most importantly, many Bostonians were highly effective in discovering that #banksyinboston was indeed a prank and spreading the word, here’s one example.
https://twitter.com/jhaley617/status/407586256881987585
And much of the discussion related to the #banksyinboston was dedicated to putting the notion to rest. This echoes the behavior observed during the London Riots in 2011.
Perspectives
So at the end of the day, did the Twitter bots have influence in Boston? We stress that this is an anecdotal test and only the most viral hashtag made it to the trending list. With a little over 800 Bostonian followers, our bots did not infiltrate Boston – and most Twitter users in Boston never interacted with one of our bots.
But what we did show was that a few dedicated bots can make a difference. In four weeks, we managed to put together a small network with substantially more impact than a single individual with a similar number of followers.
Most importantly, someone with more time & resources could easily put together a much larger system of coordinated bots that – in terms of advertisement – could be used to gently boost interest in an upcoming movie/similar. Or – with malevolent intent – could use a network of “sleeper bots” to systematically spread mis-information, e.g. injecting talking points into Twitter streams on a global scale. We hope that this little experiment can be helpful in creating awareness of such subtle manipulations before they begin shaping our public conversations.
Appendix: Twitter bots – what are those!?
Here, we provide a bit of context on Twitter bots. The earliest recorded document (that we could find) on Twitter bots is a great Ignite talk by Tim Hwang from way back in 2009.
Some of the ideas in Tim’s talk were later tested by the web ecology project, and in a class at University of Washington, and recently bots have received lots of attention in the tech and business press (e.g Wall Street Journal [Inside a Twitter Robot Factory], The Atlantic [Why Did 9,000 Porny Spambots Descend on This San Diego High Schooler?]).

Leave a reply to Simon Cancel reply