Category: Misc
-
Martin Rosvall Talk
In the Social Complexity Lab at DTU/SODAS, we’re lucky to have legendary network scientist Professor Martin Rosvall visiting soon. He will give a talk on March 10th at 14:00 at DTU (full talk details below). Martin is a brilliant network scientist and professor of physics with a focus on computational science at Umeå University, where…
-
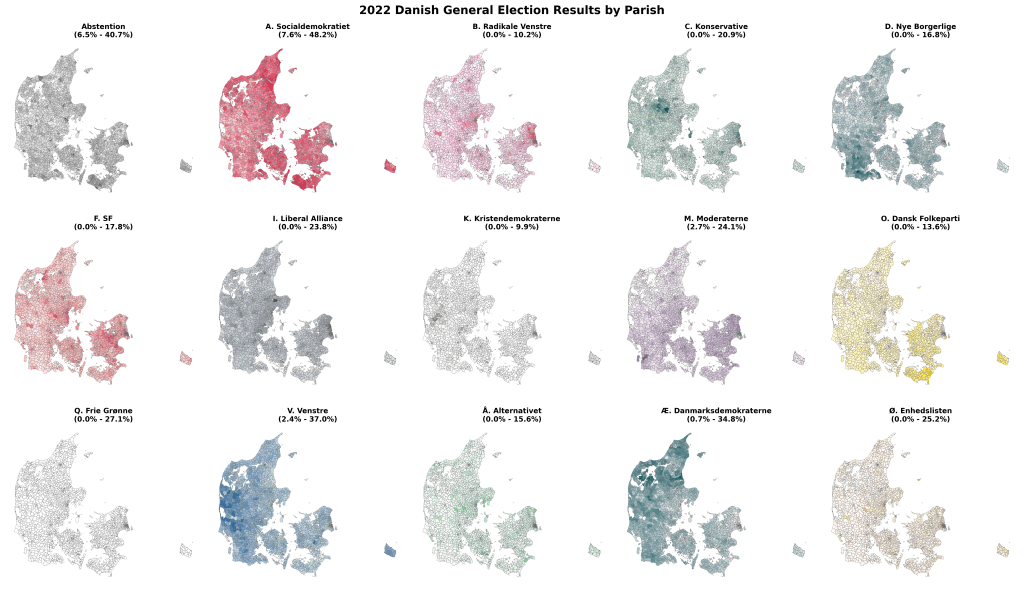
Hi-resolution voting maps of Denmark
As part of a project on something completely different, the always brilliant Louis Boucherie generated these maps of voting in Denmark during the 2022 general election [1]. Maybe it’s me, but I can’t remember seeing voting at this resolution (parishes [2]) and I found resulting images surprisingly neat & interesting, so thought it was worth…
-

Op-ed in Politiken
With the awesome Anders Søgaard, I recently wrote an Op-ed in the Danish newspaper Politiken. The op-ed is paywalled, so I’m posting a little pre-print of it here for your reading pleasure.
-

Philosophy of the Predicted Human: Cesar Hidalgo
Jonas L Juul and I are organizing a series of talks this year on the topic of The Predicted Human. Our first speaker is the amazing Cesar Hidalgo. Did I mention that Cesar is amazing? Let me give you some reasons. He’s the the Director of the Center for Collective Learning which spans the Universities…
-
Tweets I would have written. December 19, 2022 edition
It’s tough not to check Twitter, so I’m posting my random tweet ideas here:
-

Post versus Person
The setup. In this post I want to discuss the topic of filter-bubbles / echo-chambers. I think it’s dangerous to define too specifically what a filter bubble is (for reasons which will become apparent below), but the intuition is some kind of algorithmic sorting that exposes specific groups of people to content that resonates with…
-
Christoph Stadtfeld Talk
We are very excited to be joined by Christoph Stadtfeld on April 28th, where he’ll discuss The emergence of social networks and how they matter for individuals. Christoph is an Associate Professor of Social Networks at ETH Zürich. His work investigates how social networks evolve over time and how individuals are affected by the emerging…
-

Much ado …
So, recently, I won a Danish research award. A side effect of winning the award is that a bunch of Sune-material was created around it. For example, an official portrait There is also a video of me doing “research-y” stuff. And there’s even a little written “portrait” of me (in Danish). I can’t really put…
-
Oh Twitter…
Experiencing a Twitter take-down A few days ago, I was scrolling on Twitter when I came across a Twitter thread by Dr. Matthew Sweet (@drmatthewsweet) about Johann Hari’s new book Stolen Focus. I haven’t read Stolen Focus, only the parts about our work. Those parts were completely fine, see full backstory below. I don’t know…
-
My favorite talk by me
On May 20th, 2014, I gave a talk at Christiania in Copenhagen. The talk was at a cool talk-series called “Science and Cocktails”, and my talk had the title “Complex Networks: Connections, Measurements, and Social Systems“. To this day I still have fond memories of that talk. It was a packed room, in a stylish…
